
Introduction
This is broad overview of Apache Spark, and is designed as a companion piece to my 10,000ft view on Cassandra. The information is derived from the edX course Introduction to Big Data with Apache Spark, from the books Learning Spark and Advanced Analytics with Spark, and from the Spark docs.
What is Spark?
Apache Spark is a general purpose cluster computing engine. Its purpose is to allow us to do work on huge amounts of data very quickly, by taking advantage of modern cluster computing to compute at scale, and by taking advantage of the current low cost of RAM to compute in memory. This makes it much faster than its immediate predecessor, Google’s MapReduce paradigm, which relies on writing to disk during computations. It further improves on the old MapReduce by supporting interactive queries and stream processing, on top of iterative and batch processing. Spark offers APIs in Scala, Java, R and Python (MapReduce only ran in Java), and offers a richer set of possible operations on data.
Like its predecessors, Spark abstracts away the details of distributed computing such as fault tolerance and linear scalability. We just write our programs and Spark works out how many nodes to run them on, and how to recover data from failed nodes. Unlike its predecessors, the overall developer experience with Spark is quite painless. Writing Hadoop programs, for example, is notoriously tortuous. With Spark everything is much easier. And apart from anything else…Scala is awesome as we all know.
Architecture
Spark Components
Spark is made up of several components. There is the core ‘computational engine’ that is responsible for scheduling, distributing, and monitoring applications across many worker machines. Built on top of this core component are several higher-level components that are specialised for certain types of computations. The most notable of these are Spark SQL, Spark Streaming, and MLlib (a machine learning library). These components are all designed to be used together, so you can use them in your Spark programs like you would use normal libraries in your code.
The packaging up of these various components into the one super-tool that we call Spark gives us several benefits. Firstly, whenever an improvement is made to the core component the higher-level components benefit as well. Secondly, the applications that we build using Spark are easier to deploy, maintain and test than if they were built using several independent components. Finally, and most importantly in my opinion, the bundling of components allows us to build applications that use multiple processing models. For example, we can employ a streaming model in our program while also reserving batch processing capabilities for certain situations.
Here are the major components at a glance:
Spark Core – performs the basic functionality of Spark. It schedules tasks, manages memory (which, remember, is Spark’s USP in comparison to other engines), manages fault recovery, and interacts with persistent storage (Spark will write to disk on occasion). Spark Core contains the API for resilient distributed datasets (RDDs), which are Spark’s primary programming abstraction.
Spark SQL – used for working with nice structured data. Supports querying data with SQL, and supports many data formats including JSon.
Spark Streaming – enables us to perform processing on streams of data as they pass through the code. Example data streams are logfiles from web servers or streams of data on web properties that may be produced by some kind of trawler. Spark Streaming includes an API for manipulating streams that is very similar to Spark Core’s RDD API.
MLlib – short for Machine Learning library. Everyone knows that machine learning is big news at the moment due to the Big Data phenomenon. MLlib provides a number of common machine learning algorithms wrapped up in programming primitives. It also provides some programming abstractions over some of the data science tasks that support the use of these algorithms. At the moment MLlib is quite limited in terms of the data analytics that it supports, but with data analytics being to some degree the very raison d’etre for Spark itself, it receives constant attention and upgrades.
While quite different to the above components, the cluster manager (of which there are several varieties) is an important part of Spark. The cluster manager enables Spark’s massive scalability by, well, managing the cluster of Spark nodes. The Standalone Scheduler is the cluster manager that comes out of the box with Spark. Many users choose Apache Mesos or Hadoop Yarn over the Standalone Scheduler.
A Typical Program
A Spark program begins with a dataset. The typical Spark program then performs transformations on the dataset before invoking actions on it. Transformations and actions are described below.
Transformations & Actions
Transformations and actions are the two ways by which we can manipulate RDDs. A transformation allows us to create a new dataset from an existing one. Examples of transformations are filter and map. Say for example we start off with an RDD which contains the list [1, 2, 3, 4]:
ourListRdd = sc.parallelize([1, 2, 3, 4])
sc.parallelize is simply how we are turning our Scala list into an RDD. Let us now apply the filter transformation to the rdd:
ourListRdd.filter(x => x % 2 == 0)
This transformation applies the lamda function in the parentheses to the elements of the RDD and returns a new RDD which contains only the elements for which the function returns true. Therefore we are returned the list [2, 4]. How about we apply a map transformation to this new list (we can chain transformations together):
ourListRDD.filter(x => x % 2 == 0).map(x=> x * 3)
This returns a new, third RDD. What do you think it contains?
Now, a central part of the Spark programming model is that transformations are applied lazily. This means that Spark does not actually compute the various RDDs until an action is called. When an action is called, Spark looks back at the sequence of transformations and then computes them in turn. It will then send the result of the action to the machine in which the driver process is running (remember that transformations are computed in a distributed manner, across the worker nodes), or save the result to disk. What this result is depends on the contents of the RDD that it is derived from, and the particular action that is called. An example should make this clear. The action used here is collect, which returns all of the contents of an RDD as a Scala array to the driver’s machine (other actions may only return the first n elements of an RDD, for example):
firstListRdd = sc.parallelize([1, 2, 3, 4])
secondListRdd = firstListRdd.filter(x => x % 2 == 0)
thirdListRdd = secondListRdd.map(x => x * 3)
thirdListRdd.collect()
So, in this example, neither firstListRdd, secondListRdd or thirdListRdd are ever calculated until collect() is called on thirdListRdd. When collect() is called, Spark looks at the acyclic graph that it has maintained of the transformations and then computes them. The array returned contains the values 6 and 12.
At a high level, all Spark programs follow the same structure. They create RDDs from some input, they derive new RDDs from them using transformations, and perform actions to gather or save data.
The Spark Execution Model
A Spark application consists of a driver process, which is the process that the user is interacting with, and any number of executor processes distributed across the nodes of the cluster. The driver process is in charge of managing the work flow of the running applications (there can be many applications running simultaneously), while the executors are responsible for actually doing the work in the form of tasks.
At the top of Spark’s execution model are jobs. When an action is called within an application a new job is launched to fulfil the action. The job involves Spark looking at its acyclic graph for the sequence of transformations needed by the action and creating an execution plan. The execution plan involves assembling the various transformations into stages, which are run sequentially. Now, each stage corresponds to a collection of tasks, which each run the stage’s code on a different partition of the data. A discrete stage contains a sequence of transformations that can be completed without shuffling the data between nodes in the cluster.
So what determines whether or not the data has to be shuffled? Well, let’s take a look at our example dataset of [1, 2, 3, 4] and the map transformation. We could theoretically split this dataset across four nodes and carry out the map on each subset individually:
[1, 2, 3, 4].map(x => x * 2)
[1].map(x => x * 2) results in [2]
[2].map(x => x * 2) results in [4]
[3].map(x=> x * 2) results in [6]
[4].map(x => x * 2) results in [8]
Each mapping does not require knowledge of any data in any of the other subsets. However, consider the transformation GroupByKey, and an RDD of key/value pairs. If we had split our tuples across partitions we’d have to recombine them:
[(a, 1), (b, 2), (a, 4), (c, 6)].groupByKey() //each tuple is in a different //partition
(a, 1) results in (a, (1, 4)) when combined with the data in our third partition
(b, 2) results in (b, 2)
(a, 4)
(c, 6) results in (c, 6)
This moving of data across nodes is called shuffling and it is expensive. You want to avoid it as much as possible.
At the end of each stage Spark writes data to disk, which is then read by the next stage.
The acyclic graph that Spark maintains of the transformations in a program allows it to efficiently deal with node failure. The transformations can simply be reapplied to the data on that node according to the graph’s ‘recipe’, thus removing the need for data replication across nodes (as we see with Cassandra, for example). The graph also allows for the partitioning of data in the first place, because as long as each executor has the graph, computations on a dataset can be performed in parallel by splitting up the dataset among the executors.
Running Spark Applications in a Cluster
It’s possible to run Spark in local mode, whereby the driver process and executor processes all run in the same Java process. This is useful for development, but really Spark is interesting when it’s running on a distributed cluster of computers, in distributed mode.
As we hinted at before, Spark employs a master/slave architecture with one driver process coordinating the actions of distributed executor processes. The driver and the executors each run in their own Java process. The driver is where a Spark program’s main() method runs, and it is where the important SparkContext object is created (we will explain the SparkContext later on). It is also where RDDs are created.
The driver has two duties. Firstly it converts the program’s acyclic graph of transformations into an execution plan (which consists of stages, which consist of tasks). The plan’s tasks are sent by the driver to the executors to be computed. Secondly, the driver coordinates the scheduling of individual tasks on executors.
Executors also have two duties. Firstly, they run the tasks sent to them by the driver and return to it the results of the tasks. Secondly, they provide in-memory storage for RDDs that applications instruct them to cache (this is a key feature of Spark programming).
Whenever a Spark application is run in a cluster, the following sequence of events occur:
- The user submits an application using the spark-submit command or Spark JobServer.
- spark-submit or Spark JobServer launch the driver program and invokes its main() method.
- The driver asks the cluster manager to launch executors for it.
- The cluster manager obliges, and launches executors.
- The driver runs the application, sending tasks to the executors based on the acyclic graph of the application.
- Tasks run on the executors to compute and save results.
- If the driver’s main() method exits or calls SparkContext.stop() the driver will terminate the executors.
Using Spark
Thus far I have taken it for granted that you, dear reader, are using Scala for all your Spark programming needs. But we can also program with Spark in Java, Python and R. So why do we favour Scala? The short answer is that Scala is awesome. However, there are some other powerful arguments for using Scala with Spark that generalise to all use cases. Firstly, Spark itself is written in Scala. This means that your Scala programs are guaranteed to run that bit more seamlessly on the Spark platform than they would if they were written in Python, Java or R. Secondly, since Scala is Spark’s favoured child the Scala versions of the various components/libraries are upgraded before the other versions.
So how do we go about using Spark with Scala? Here I will present an example batch application accompanied by commentary. The example is from the Spark docs:
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
import org.apache.spark.SparkConf
object SimpleApp {
def main(args: Array[String]) {
val logFile = “YOUR_SPARK_HOME/README.md”
val conf = new SparkConf().setAppName(“Simple Application”).setMaster(“local”)
val sc = new SparkContext(conf)
val logData = sc.textFile(logFile).cache()
val numAs = logData.filter(line => line.contains(“a”)).count()
val numBs = logData.filter(line => line.contains(“b”)).count()
println(“Lines with a: %s, Lines with b: %s”.format(numAs, numBs))
}
}
So what’s going on in this simple example which is counting the number of occurrences of the letters ‘a’ and ‘b’ in the README file? Inside the main method, we first initialise a simple String object which will be used to create our first RDD later on. Every Spark program must create a SparkContext object which tells Spark how to access the cluster. This SparkContext object needs to be passed a SparkConf which contains information about our particular application. In this example we tell the SparkContext what our application is called, and what URL to use to connect to the cluster. In this case we are telling it to run in local mode.
With a reference to a data source, a SparkContext, and a SparkConf we are now ready to initialise our first RDD (‘logData’). We do by calling textFile() on our SparkContext, and passing it the path to the text file that we want to turn into an RDD. We cache the RDD so that it is saved in memory for when we want to run the application again. This means that when Spark looks at its graph to see what it has to compute, it need not initialise the RDD from the text file a second time. In this way we can save a lot of expensive IO.
Once we have our first RDD we can create new RDDs by applying transformations to it (filter() in this case). Since our program calls the count() action on the RDD that results from applying filter() to logData, Spark computes the RDDs in its graph and returns the final result as a Long to the machine in which the driver process is running. Finally we print the two Long values to the console in the driver’s machine.
Interacting with C*
Spark can talk to Cassandra via DataStax’s Spark Cassandra Connector. We add a dependency to the Connector in our build.sbt file (more on that later), and import the Connector libraries in our application:
import com.datastax.spark.connector._
We can then read from the ‘asset’ table, which is in our ‘assets’ keyspace, like so:
val assetRdd = sc.cassandraTable(“assets”, “asset”)
The above call to Cassandra returns an RDD of key/value pairs, where the key is the column name and the value is a value in the table for that column.
We can write to Cassandra using the saveToCassandra() method that comes with the Spark Cassandra Connector:
assetRdd.saveToCassandra(“assets”, “asset”, AllColumns)
In the above method call we again specify the keyspace and table that we want to save the contents of our RDD to. We also specify the columns in the table that we want to save to. In this case assetRdd has data for every column in the asset table so we don’t need to be specific. We can use ‘AllColumns’. (Note that were we to use the above two calls one after the other in a program, then the call to saveToCassandra would simply be reinserting data that already exists in the table, and the table would not change.)
Deploying Applications in Spark
You have two options if you want to deploy a Spark application:
- spark-submit
- Spark JobServer
spark-submit is the command line program that comes packaged with Spark. It is used to launch an application like so:
spark-submit --class com.gintycorp.stream.sucker.StreamSucker --master spark://colm.gintycorp.com:7077 --deploy-mode client /home/colm/projects/sucker/target/scala-2.10/sucker-assembly-1.2.12.jar local
Regarding the parameters, we are specifying:
- the url of the cluster master to which we are sending the jar and which will distribute the code to its workers
- the deploy mode, which is client in this case. Deploying a Spark application in client mode means that the driver will be external to the actual physical cluster of machines that are running the workers, usually meaning on your local machine. If deployed in cluster mode, the driver will live on a machine in the cluster.
- the jar that we are deploying
- finally, a String parameter which is used by our code to determine the environment in which it’s running (e.g. local, prod, ver)
Spark JobServer is a server that provides a RESTful way to launch Spark applications. We can use it to launch applications from REST services. With the JobServer running in our environment we can upload to it a jar containing our application code, via curl:
curl --data-binary @../../target/scala-2.10/stream-sucker-assembly-1.2.6.jar localhost:8090/jars/interfaceBuilder
We can then kick off a interfaceBuilder job by submitting a request to the REST service.
Spark Web UI
Spark provides a web interface which allows you to track the progress of your jobs, and to query the logs. It is available at 8080 and 4040 by default.
Build.sbt
So how do we build our Spark applications? Well, assuming they are Scala programs, we build them as we do any other Scala program. As mentioned above, there is a file called build.sbt which lives at the root of the Scala project and is roughly equivalent to the root pom of a Maven project. This is the dependencies section of an example build.sbt from Learning Spark:
libraryDependencies ++= Seq(
"org.apache.spark" %% "spark-core" % "1.3.1" % "provided",
"org.apache.spark" %% "spark-sql" % "1.3.1",
"org.apache.spark" %% "spark-hive" % "1.3.1",
"org.apache.spark" %% "spark-streaming" % "1.3.1",
"org.apache.spark" %% "spark-streaming-kafka" % "1.3.1",
"org.apache.spark" %% "spark-streaming-flume" % "1.3.1",
"org.apache.spark" %% "spark-mllib" % "1.3.1",
"org.apache.commons" % "commons-lang3" % "3.0",
"org.eclipse.jetty" % "jetty-client" % "8.1.14.v20131031",
"com.typesafe.play" % "play-json_2.10" % "2.2.1",
"com.fasterxml.jackson.core" % "jackson-databind" % "2.3.3",
"com.fasterxml.jackson.module" % "jackson-module-scala_2.10" % "2.3.3",
"org.elasticsearch" % "elasticsearch-hadoop-mr" % "2.0.0.RC1",
"net.sf.opencsv" % "opencsv" % "2.0",
"com.twitter.elephantbird" % "elephant-bird" % "4.5",
"com.twitter.elephantbird" % "elephant-bird-core" % "4.5",
"com.hadoop.gplcompression" % "hadoop-lzo" % "0.4.17",
"mysql" % "mysql-connector-java" % "5.1.31",
"com.datastax.spark" %% "spark-cassandra-connector" % "1.0.0-rc5",
"com.datastax.spark" %% "spark-cassandra-connector-java" % "1.0.0-rc5",
"com.github.scopt" %% "scopt" % "3.2.0",
"org.scalatest" %% "scalatest" % "2.2.1" % "test",
"com.holdenkarau" %% "spark-testing-base" % "0.0.1" % "test"
)
Libraries
As mentioned above, Spark includes several components which are tightly integrated with Spark Core, and which are interoperable. They can be used together in Spark programs just like third party libraries.
Spark SQL
Spark SQL is Spark’s interface for working with structured and semistructured data. Structured data is any data that has a schema, such as JSon. Spark SQL provides us with DataFrames, which are a programming abstraction designed to simplify the process of working with structured data. A DataFrame is sort of like a table in a relational database.
Spark Streaming
Spark Streaming enables the processing of live data streams from sources such as Twitter, Kafka (a queuing system) and TCP sockets. We can apply the transformations to the stream data, for example filtering the data as it comes in to create a sub-stream of the original stream, just as we create a new smaller RDD by applying filter to an RDD. We can also combine Spark components by applying the algorithms of MLlib to streams of data.
Internally, Spark Streaming works by splitting up incoming data streams into discrete batches. These batches are then fed into a Spark application, which produces a result as a ‘stream’, which is a stream of batches.
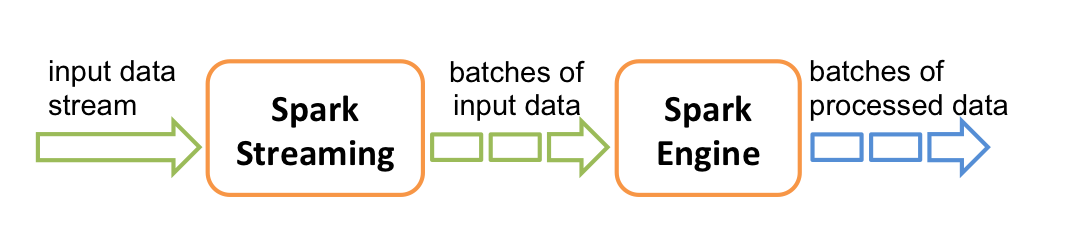
Just as Spark Core provides us with RDDs as a high level abstraction over input datasets, Spark Streaming provides us with DStreams. DStreams represent a continuous stream of data, although as mentioned above they are actually a stream of batches of data. In fact, internally DStreams are a sequence of RDDs. Analogous to RDDs, DStreams can be created either from input data streams or by applying transformations to existing DStreams.
Here follows an example Spark Streaming program. It comes from the Spark docs:
import org.apache.spark._
import org.apache.spark.streaming._
import org.apache.spark.streaming.StreamingContext._
Just as we need a SparkContext object for a batch program, we need a StreamingContext object for a streaming program. As well as passing a SparkConf to the StreamingContext we can set the time interval by which to delineate batches of stream data. I.e. we will start a new batch every x seconds.
val conf = new SparkConf().setMaster("local").setAppName("NetworkWordCount")
val ssc = new StreamingContext(conf, Seconds(1))
Using this context we here create a DStream that represents streaming data coming from a TCP source, specified as hostname and port (localhost and 9999 in this case).
val lines = ssc.socketTextStream("localhost", 9999)
This lines DStream represents the stream of data that comes in via the TCP connection. Each record in this DStream is a line of text. Next, we want to split the lines by space characters into words.
val words = lines.flatMap(_.split(" "))
flatmap here splits each line into multiple words and the stream of words is represented as the words DStream. Next, we want to count these words.
val pairs = words.map(word => (word, 1))
val wordCounts = pairs.reduceByKey(_ + _)
wordCounts.print()
The words DStream is mapped to a DStream of (word, 1) pairs, which is then reduced to get the frequency of words in each batch of data. Finally, wordCounts.print() will print the counts that are generated every second.
Note that we have not called an action yet. In this case we are not looking to do anything other than print to the console, and the print() function is not a Spark action. In order to kick off the computation of the transformations we can call the following:
ssc.start()
ssc.awaitTermination()
MLlib
MLlib is Spark’s machine learning library. As mentioned in our Spark Components section, Spark provides abstractions over many common machine learning algorithms and tasks. Not every machine learning algorithm is provided – some algorithms are not suitable for parallel computations over multiple nodes. In these cases Spark can provide no advantage over existing libraries that include these algorithms.
Ultimately, an MLlib program is the same as a Spark Streaming or batch program – it consists of functions called on RDDs. All of the actual data science is hidden under the hood. To use the library effectively, of course, you must have some understanding of data science pipelines (i.e. given a data set and an objective, which tasks and algorithms do I wish to apply). I believe, however, that it is possible to do useful data science using MLlib while only having a rudimentary grasp of data science fundamentals. The two books Data Smart and Data Science for Business contain much of the information that you need.
Conclusion
That is Apache Spark from a high level. In-memory processing and lazy evaluation are the secret sauce, but it pays to have an understanding of the nuts and bolts of the architecture and execution model as well. Hopefully the above will give you that. Also, I hope that I have given you something of a feel of what working with Spark is like, via the examples and the deployment information.
The book Learning Spark has mediocre reviews on Amazon, mostly due to the fact that it is just a repackaging of the information that is already available for free online in the form of the Spark official documentation. However, if you’re like me and you like your technical info neatly organised in book form you will find Learning Spark very valuable. Advanced Analytics in Spark is a book on using Spark for data science, so if you are interested in that give it a look. Finally, the edX course Introduction to Big Data with Apache Spark is informative, and will also help you to exercise your functional chops.
